Как глубокое обучение позволило компьютерам видеть
Одна из самых больших задач ۲۱-го века — сделать компьютеры более похожими на человеческий мозг. Мы хотим, чтобы они говорили, понимали и решали проблемы — а теперь мы хотим, чтобы они видели и распознавали изображения. Долгое время наши самые умные компьютеры были слепыми. Теперь они могут видеть. Это революция, ставшая возможной благодаря глубокому обучению.
Понять машинное обучение довольно просто. Идея заключается в том, чтобы обучать алгоритмы на больших базах данных, чтобы они могли предсказывать результаты из новых данных. Вот простой пример: мы хотим предсказать возраст дерева по его диаметру. Эта база данных содержит только три типа данных: вход (x, диаметр дерева), выход (y, возраст дерева) и признаки (a, b: тип дерева, местоположение леса …). Эти данные связаны линейной функцией y = ax + b. С обучением этой базы данных алгоритмы машинного обучения смогут понять корреляцию между x и y и определить точное значение признаков. После завершения этой фазы обучения компьютеры смогут предсказывать правильный возраст дерева (y) по любому новому диаметру (x).
Это слишком упрощенное описание; оно становится более сложным, когда мы говорим о распознавании изображений. Для компьютера картинка — это миллионы пикселей, то есть очень много данных для обработки и слишком много входных данных для одного алгоритма. Исследователям пришлось найти обходной путь. Первое решение заключалось в определении промежуточных характеристик. Представьте, что вы хотите, чтобы компьютеры распознавали кошку. Прежде всего, человек должен определить все основные черты кошки: круглая голова, два острых уха, морда … После определения ключевых черт, хорошо обученный алгоритм нейронной сети с достаточной точностью проанализирует их и определит, является ли изображение кошкой.
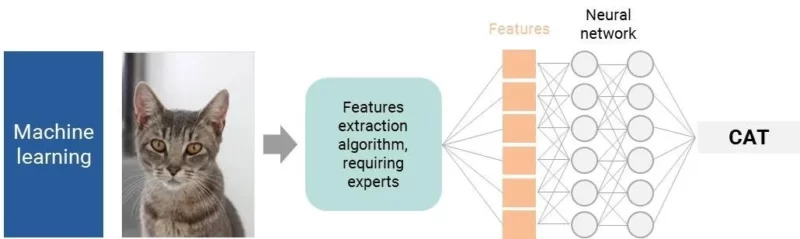
?А что, если мы возьмем более сложный предмет? Например, как вы описали бы платье компьютеру

Вы получите первый предел базового машинного обучения для распознавания изображений: мы часто не способны определить дискриминационные характеристики, которые привели бы к ۱۰۰% вероятности распознавания.
Глубокое обучение: видение и обучение без вмешательства человека
В ۲۰۰۰-х годах Фей-Фей Ли, директор лаборатории искусственного интеллекта и лаборатории зрения Стэнфорда, имела хорошую интуицию: как дети учатся именам объектов? Как они могут распознать кошку или платье? Родители не учат этому, показывая характеристики, а скорее называя объект/животное каждый раз, когда ребенок его видит. Они обучают детей визуальными примерами. Почему мы не можем сделать то же самое для компьютеров?
Однако, остались две проблемы: доступность баз данных и вычислительная мощность. Во-первых, как мы можем получить достаточно большую базу данных, чтобы «научить компьютеры видеть»? Чтобы решить эту проблему, Ли и ее команда запустили проект ImageNet в ۲۰۰۷ году. В сотрудничестве с более чем ۵۰ ۰۰۰ человек в ۱۸۰ странах они создали самую большую в мире базу данных изображений в ۲۰۰۹ году: ۱۵ миллионов названных и классифицированных изображений, охватывающих ۲۲ ۰۰۰ категорий.
Теперь компьютеры могут обучать себя на огромных базах данных изображений, чтобы идентифицировать ключевые черты, и без вмешательства человека. Как ребенок в три года, компьютеры видят миллионы названных изображений и сами понимают основные характеристики каждого предмета. Эти сложные алгоритмы извлечения признаков используют глубокие нейронные сети и требуют тысяч миллионов узлов.
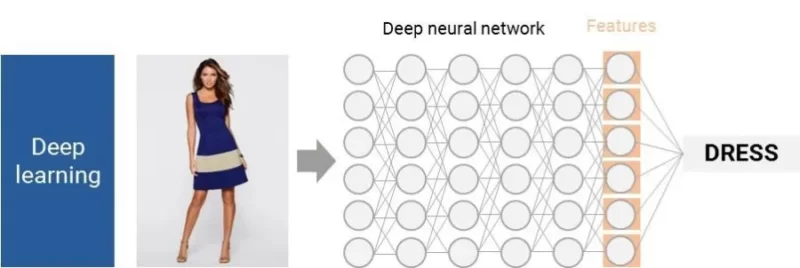
Это только начало для глубокого обучения: мы смогли заставить компьютеры видеть, как ребенок в три года, но, как сказала Ли в TED Talk, «перед нами стоит реальная проблема: как мы можем помочь нашему компьютеру перейти от трехлетнего ребенка к тринадцатилетнему и далеко за пределы этого?»