كيف مكن التعلم العميق الحواسيب من الرؤية
يُعدّ أحد أكبر تحديات القرن الحادي والعشرين جعل الحواسيب أقرب إلى دماغ الإنسان. فنحن نريدها أن تتحدث، وتفهم، وحل المشكلات – والآن نريدها أن ترى وتتعرف على الصور. لفترة طويلة، كانت أقوى حواسيبنا عمياء. الآن، يمكنها أن ترى. هذه ثورة أصبحت ممكنة بفضل التعلم العميق.
فهم التعلم الآلي سهل للغاية. الفكرة هي تدريب الخوارزميات على قواعد بيانات ضخمة لتمكينها من التنبؤ بالنتائج من البيانات الجديدة. هنا مثال بسيط: نريد التنبؤ بعمر شجرة بناءً على قطرها. تحتوي قاعدة البيانات هذه على ثلاثة أنواع من البيانات فقط: المدخل (x، قطر الشجرة)، المخرج (y، عمر الشجرة) والخصائص (a، b: نوع الشجرة، موقع الغابة …). ترتبط هذه البيانات بوظيفة خطية y = ax + b. مع تدريب هذه قاعدة البيانات، ستتمكن خوارزميات التعلم الآلي من فهم العلاقة بين x و y وتحديد القيمة الدقيقة للخصائص. بمجرد اكتمال مرحلة التدريب، ستتمكن الحواسيب من التنبؤ بعمر الشجرة الصحيح (y) من أي قطر جديد (x).
هذا وصف مبسط للغاية. تصبح الأمور أكثر تعقيدًا عند الحديث عن التعرف على الصور. بالنسبة للحاسوب، تُعد الصورة ملايين من البكسل – وهذا يعني الكثير من البيانات لمعالجتها، وكثير من المدخلات لخوارزمية واحدة. كان على الباحثين إيجاد اختصار. كان الحل الأول هو تحديد خصائص وسيطة. تخيل أنك تريد أن تجعل الحواسيب تتعرف على قطة. أولاً، يجب على الإنسان تحديد جميع الميزات الرئيسية للقطة: رأس مستدير، أذنان حادتان، أنف … بمجرد تحديد الميزات الرئيسية، ستقوم خوارزمية الشبكة العصبية المدربة جيدًا، مع مستوى دقة كافٍ، بتحليلها وتحديد ما إذا كانت الصورة لقطة أم لا.
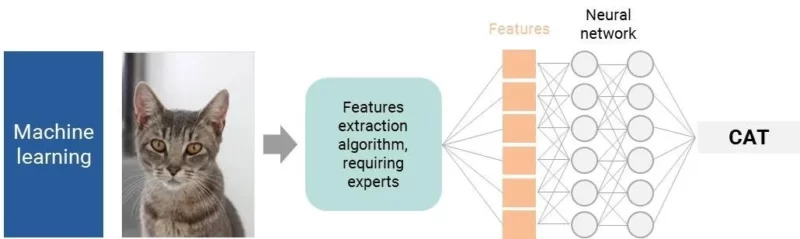
ماذا لو أخذنا عنصرًا أكثر تعقيدًا؟ على سبيل المثال، كيف ستصف فستانًا لحاسوب؟

هنا تصل إلى أول حدود التعلم الآلي الأساسي للتعرف على الصور: غالبًا ما نكون غير قادرين على تحديد الخصائص التمييزية التي من شأنها أن تؤدي إلى احتمال ۱۰۰٪ للتعرف.
التعلم العميق: الرؤية والتعلم دون تدخل بشري
في العقد الأول من القرن الحادي والعشرين، كانت لدى في-في لي، مديرة مختبر الذكاء الاصطناعي ومختبر الرؤية في جامعة ستانفورد، حدس جيد: كيف يتعلم الأطفال أسماء الأشياء؟ كيف يتمكنون من التعرف على قطة أو فستان؟ لا يُعلمهم الآباء ذلك من خلال عرض الخصائص، بل من خلال تسمية الجسم/الحيوان في كل مرة يراه الطفل. يقومون بتدريب الأطفال من خلال أمثلة مرئية. لماذا لا يمكننا فعل الشيء نفسه للحواسيب؟
ومع ذلك، ظلت مشكلتان: توفر قواعد البيانات وقوة الحوسبة. أولًا، كيف يمكننا الحصول على قاعدة بيانات كبيرة بما يكفي “للتعليم على رؤية الحواسيب”؟ للتعامل مع هذه المشكلة، أطلقت لي وفريقها مشروع ImageNet في عام ۲۰۰۷٫ بالتعاون مع أكثر من ۵۰٫۰۰۰ شخص في ۱۸۰ دولة، أنشأوا أكبر قاعدة بيانات للصور في العالم في عام ۲۰۰۹: ۱۵ مليون صورة مسماة ومصنفة، تغطي ۲۲٫۰۰۰ فئة.
يمكن للحواسيب الآن تدريب نفسها على قواعد بيانات ضخمة للصور لتمكنها من تحديد الميزات الرئيسية، بدون تدخل بشري. مثل طفل يبلغ من العمر ثلاث سنوات، ترى الحواسيب ملايين الصور المسماة وتفهم بنفسها الخصائص الرئيسية لكل عنصر.
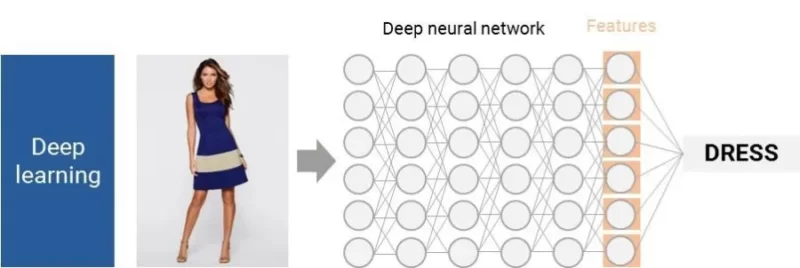
تستخدم هذه الخوارزميات المعقدة لاستخراج الميزات الشبكات العصبية العميقة وتتطلب آلاف ملايين العقد. إنها مجرد بداية للتعلم العميق: نجحنا في جعل الحواسيب ترى مثل طفل يبلغ من العمر ثلاث سنوات، ولكن، كما قالت لي في محاضرة TED، “التحدي الحقيقي في المستقبل: كيف يمكننا مساعدة حاسوبنا على الانتقال من عمر ثلاث سنوات إلى ۱۳ عامًا و ما بعد ذلك؟”