


چطور یادگیری عمیق به کامپیوترها اجازه دیدن داد؟
یکی از بزرگترین چالشهای قرن بیست و یکم، ساخت کامپیوترهایی با قابلیتهایی شبیه به مغز انسان است. ما میخواهیم که آنها صحبت کنند، بفهمند، مشکلات را حل کنند و حالا میخواهیم که ببینند و تصاویر را تشخیص دهند. مدتها بود که قدرتمندترین کامپیوترهای ما نابینا بودند. حالا، آنها میتوانند ببینند. این انقلابی است که با کمک یادگیری عمیق به وجود آمده است.
درک یادگیری ماشین بسیار آسان است. ایده این است که الگوریتمها را بر روی پایگاه دادههای بزرگ آموزش دهیم تا آنها بتوانند از دادههای جدید نتیجهگیری کنند. به عنوان مثال، میخواهیم سن یک درخت را بر اساس قطر آن پیش بینی کنیم. این پایگاه داده فقط سه نوع اطلاعات دارد: ورودی (x، قطر درخت)، خروجی (y، سن درخت) و ویژگی ها (a، b: نوع درخت، مکان جنگل…). این اطلاعات توسط یک تابع خطی y = ax + b به هم مرتبط هستند. با آموزش این پایگاه داده، الگوریتمهای یادگیری ماشین قادر به درک ارتباط بین x و y و تعیین مقدار دقیق ویژگی ها خواهند بود. پس از اتمام این مرحله آموزشی، کامپیوترها قادر خواهند بود سن دقیق درخت (y) را از قطر جدید (x) پیش بینی کنند.
این یک توصیف بیش از حد ساده است. وقتی صحبت از تشخیص تصویر میشود، اوضاع پیچیدهتر است. برای یک کامپیوتر، یک تصویر میلیونها پیکسل است – یعنی حجم زیادی از دادهها برای پردازش و ورودیهای زیادی برای یک الگوریتم. محققان مجبور بودند راهی میانبر پیدا کنند. اولین راه حل این بود که ویژگیهای واسطهای تعریف کنند.
تصور کنید که میخواهید کامپیوترها یک گربه را تشخیص دهند. اول از همه، یک انسان باید تمام ویژگیهای اصلی یک گربه را تعریف کند: سر گرد، دو گوش تیز، پوزه… پس از تعریف ویژگیهای کلیدی، یک الگوریتم شبکه عصبی آموزش دیده با دقت کافی، آنها را تجزیه و تحلیل کرده و تعیین میکند که آیا تصویر یک گربه است یا خیر.
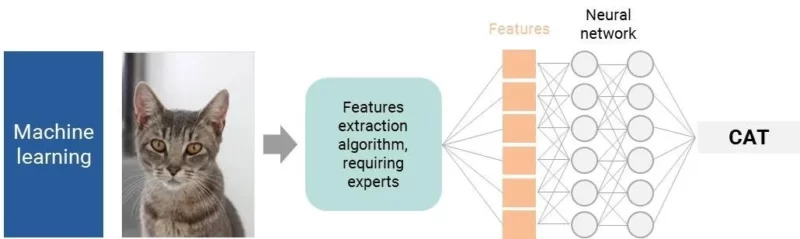
حالا چه میشود اگر یک مورد پیچیدهتر را در نظر بگیریم؟ به عنوان مثال، چگونه یک لباس را برای یک کامپیوتر توصیف میکنید؟

به این ترتیب به اولین محدودیت یادگیری ماشین پایه برای تشخیص تصویر میرسیم: ما اغلب قادر به تعریف ویژگیهای تمییز کنندهای نیستیم که به احتمال ۱۰۰ درصد منجر به تشخیص شود.
یادگیری عمیق: دیدن و یادگیری بدون دخالت انسان
در دهه ۲۰۰۰، فی-فی لی، مدیر آزمایشگاه هوش مصنوعی و آزمایشگاه بینایی دانشگاه استنفورد، یک شهود خوب داشت: کودکان چگونه نام اشیاء را یاد میگیرند؟ چگونه میتوانند یک گربه یا یک لباس را تشخیص دهند؟ والدین این را با نشان دادن ویژگیها آموزش نمیدهند، بلکه هر زمان که فرزندشان یک شیء/حیوان را میبیند، نام آن را به او میگویند. آنها کودکان را با مثالهای بصری آموزش میدهند. چرا نمیتوانیم همین کار را برای کامپیوترها انجام دهیم؟
با این حال، دو مشکل باقی ماند: در دسترس بودن پایگاه دادهها و قدرت محاسباتی. اولا، چگونه میتوانیم پایگاه دادهای به اندازه کافی بزرگ برای “آموزش دیدن به کامپیوترها” بدست آوریم؟ برای حل این مشکل، لی و تیمش در سال ۲۰۰۷ پروژه ImageNet را راه اندازی کردند. آنها با همکاری بیش از ۵۰۰۰۰ نفر در ۱۸۰ کشور، در سال ۲۰۰۹ بزرگترین پایگاه داده تصویری جهان را ایجاد کردند: ۱۵ میلیون تصویر نامگذاری شده و طبقه بندی شده، در ۲۲۰۰۰ دسته.
حالا کامپیوترها میتوانند خودشان را بر روی پایگاههای داده تصویری عظیم آموزش دهند تا بتوانند ویژگیهای کلیدی را شناسایی کنند، و بدون دخالت انسان. مانند یک کودک سه ساله، کامپیوترها میلیونها تصویر نامگذاری شده را میبینند و به طور خودکار ویژگیهای اصلی هر مورد را درک میکنند. این الگوریتمهای پیچیده استخراج ویژگی از شبکههای عصبی عمیق استفاده میکنند و به هزاران میلیون گره نیاز دارند.
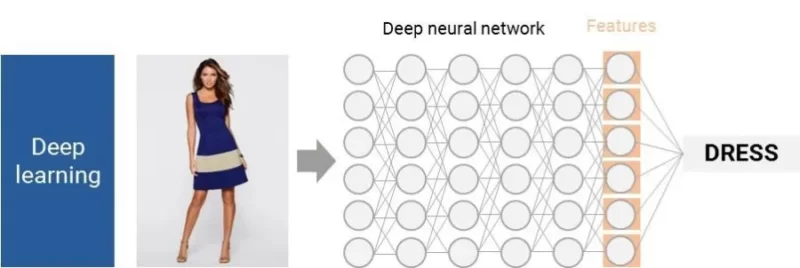
این فقط آغاز یادگیری عمیق است: ما موفق شدیم کامپیوترها را مانند یک کودک سه ساله ببینیم، اما، همانطور که لی در یک سخنرانی TED گفت، “چالش واقعی در پیش است: چگونه میتوانیم به کامپیوترمان کمک کنیم تا از سه سالگی به یک نوجوان ۱۳ ساله و فراتر از آن تبدیل شود؟”
- نویسنده : حامد غلامی
- منبع خبر : TechCrunch



